# Procesor
Moduł procesora odpowiada za przetwarzanie danych strumieniowych w czasie rzeczywistym, udostępnianych przez moduł kolektora. Procesor udostępnia dwa systemy obsługi danych strumieniowych - wysokopoziomowy szkielet przetwarzania danych strumieniowych Apache Flink i 'Custom image' który pozwala na załadowanie kontenera z własną implementacją funkcji przetwarzających. Każdy flow może używać tylko jeden wybrany system procesora. Implementacja procesora musi obsługiwać połączenie z Apache Kafka i wybranym mechanizmem Storage w celu otrzymania danych z Kolektora i zapisania wyniku obliczeń w Emiterze.
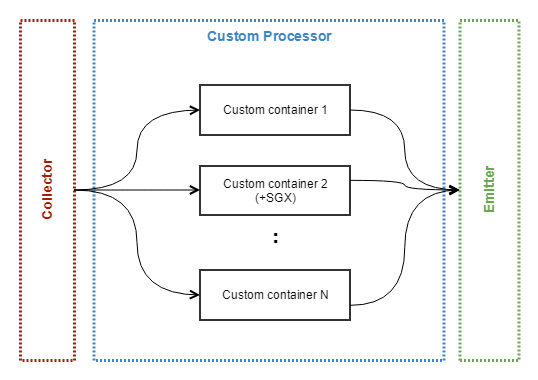
# Custom
Tryb procesora który umożliwia załadowanie własnego obrazu kontenera Dockera do klastra. Konfiguracja użytkownika pozwala na przydzielenie określonej ilości zasobów dla kontenera (CPU i RAM) oraz uruchomienie go w określonej liczbie replik. Dostępny też jest autoskaler pozwalający na zwiększenie liczby replik i tym samym zrównoleglenie obliczeń przy większym zużyciu zasobów. W tej opcji możliwe jest wybranie wsparcia Intel SGX dla kontenera.
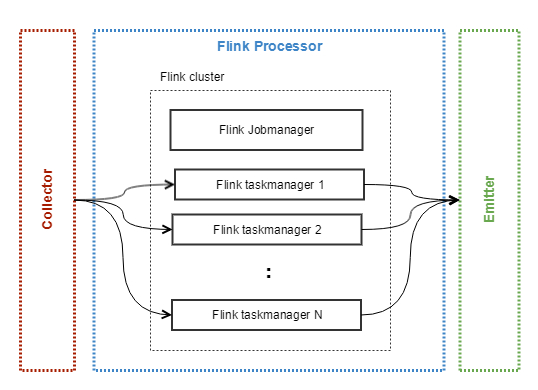
# Apache Flink
Ten typ procesora uruchamia klaster Apache Flink. Użytkownik może zdefiniować ilość replik, przydzielenie zasobów(CPU i RAM) oraz autoskalowanie ze względu na obciążenie managerów zadań (ang. task manager), które odpowiadają za wykonywanie obliczeń. Logika przetwarzania danych musi być zaimplementowana przez użytkownika systemu zgodnie z dokumentacją szkieletu i skompilowana. Tak przygotowany program musi zostać wgrany do klastra przez API albo interfejs Webowy.