Disaster Recovery (DR), czyli odtwarzanie awaryjne, to zbiór procedur i polityk pozwalający na wznowienie lub utrzymanie infrastruktury IT po poważnej awarii. Awaria może być skutkiem szkodliwej działalności człowieka (nieumyślnej lub umyślnej, jak np. cyberatak) czy klęski żywiołowej (pożar, powódź, trzęsienie ziemi, tsunami itp.). Katastrofa może spowodować uszkodzenie infrastruktury i uniemożliwić działalność biznesową. Dzisiaj mało kto może sobie pozwolić na dłuższy przestój, oznaczający nie tylko brak dostępności usług, ale i utratę danych klientów. Dlatego każda organizacja powinna posiadać Disaster Recovery Plan a w jego ramach wyznaczone Disaster Recovery Center (DRC) czyli miejsce gdzie systemy informatyczne zostaną odtworzone.
Czytaj dalejKategoria: technologie chmury
Co to jest wysoka dostępność?
Wysoka dostępność (ang. High Availability, w skrócie HA) to odporność poszczególnych komponentów infrastruktury informatycznej na awarię, która umożliwia funkcjonowanie uruchomionych aplikacji bez zakłóceń. HA jest szczególnie ważne w przypadku krytycznych systemów, dla których przestój w działaniu oznacza poważne szkody, również finansowe. Jednym z głównych celów przejścia do chmury jest właśnie osiągnięcie niezawodności.
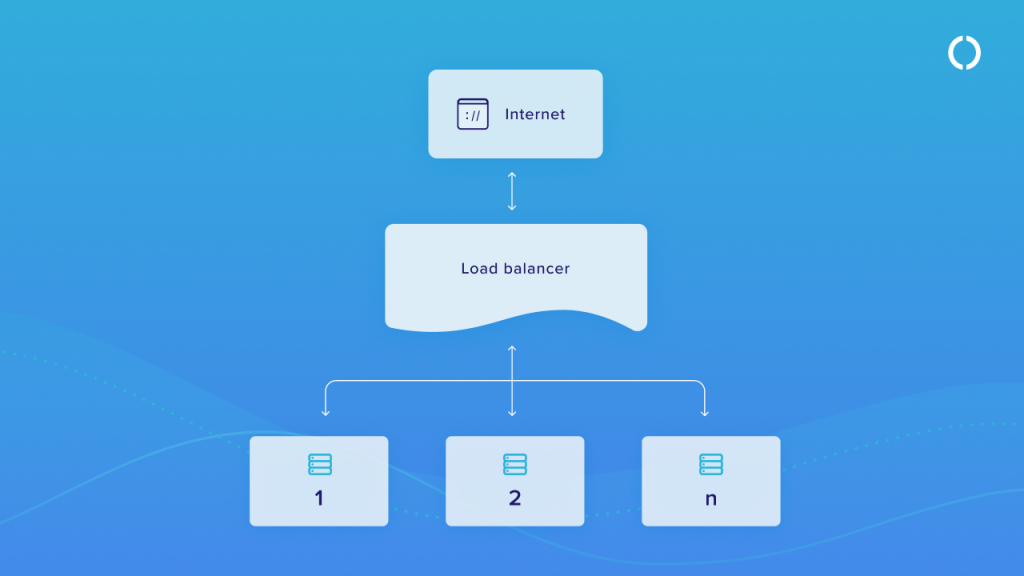
Systemy o wysokiej dostępność eliminują pojedyncze punkty awarii (SPOF), aby zapewnić ciągłość działania i uchronić firmę przed utratą danych. Pojedynczy punkt awarii to dowolny element systemu, którego nieprawidłowe działanie mogłoby spowodować awarię całego systemu. Wysoką dostępność uzyskuje się zwykle przez konfigurację minimum dwu lub więcej serwerów obsługujących tę samą aplikację. Gdy jeden serwer ulegnie awarii, system automatycznie przełącza klientów na drugi, sprawnie działający. Systemy wysokiej dostępności mogą być również budowane z uwzględnieniem zabezpieczenia na poziomie geograficznym.
Wysoka dostępność jest zwykle wyrażaną w procentach, oznaczających długość czasu pracy bez przestoju. Na przykład system, o HA wynoszącym 99,99% gwarantuje, że maksymalnie czas przestoju wyniesie 52,6 minuty w ciągu roku.
Co to jest konteneryzacja?
Powstanie technologii konteneryzacji to konsekwencja dążenia twórców aplikacji do architektury mikroserwisów. Zarządzanie złożonymi, rozproszonymi systemami mikroaplikacji stało się sporym wyzwaniem logistycznym, stąd odniesienie do idei kontenerów w branży logistycznej.
Czytaj dalejCo to są mikroserwisy?
Mikroserwisy to termin określający architekturę aplikacji i sposób ich pisania. W odróżnieniu od monolitycznych rozwiązań, których zasada działania opiera się na rozmieszczeniu poszczególnych części aplikacji w jej wnętrzu (z wykorzystaniem relacyjnego modelu danych), mikroserwisy dzielą je na mniejsze, niezależne od siebie komponenty.
Mikroserwisy są zatem oddzielnymi częściami tej samej aplikacji – komponentami lub procesami. Umożliwiają programistom pracę nad elementami aplikacji bez ingerencji w jej całą architekturę. Przyspieszają proces tworzenia oprogramowania, czynią aplikację lżejszą. Zapobiegają awarii całego systemu (jeśli pojawi się problem, to tylko w jednym komponencie).
Mikroserwisy są ściśle powiązane z architekturą kontenerową. To właśnie dzięki kontenerom możliwe jest sprawne zarządzanie mikrousługami i w związku z tym stworzenie aplikacji opartej na współpracujących ze sobą serwisach (modułach).
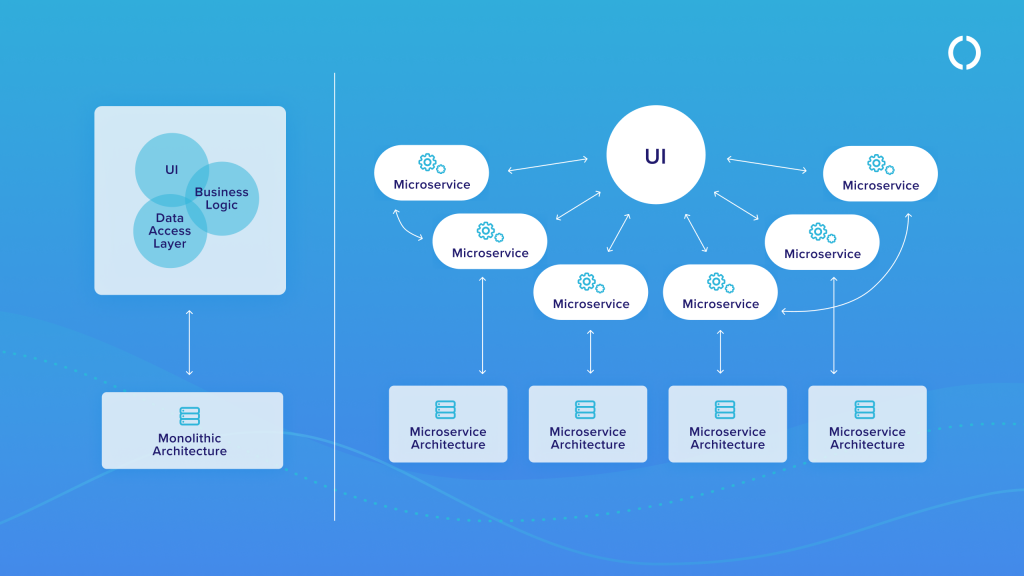
Geneza powstania mikroserwisów
Problemy związane z aplikacjami monolitycznymi zostały zauważone jeszcze na długo przed wdrożeniem mikroserwisów. Pierwszą próbą ich rozwiązania była architektura zorientowana na usługi, czyli SOA (Service Oriented Architecture).
SOA miała takie same założenia jak mikroserwisy. Chodziło o to, aby rozbić rozbudowany system na mniejsze, współpracujące ze sobą usługi. Wdrożenie takiej architektury wymagało jednak wykorzystania szyny integracyjnej, czyli ESB (Enterprise Service Bus). Ta odpowiadała za całą masę procesów m.in.: routing, mapowanie i audytowanie. Niestety, właśnie wielozadaniowość ESB stała się jej największą wadą. Szyny zaczęły się przeradzać w kolejną aplikację monolityczną, przez co architektura SOA przestała się dłużej sprawdzać.
Mikroserwisy są de facto ulepszoną wersją SOA. Dzięki postępom w technologii kontenerowej spełniają założenia architektury zorientowanej na usługi, ale jednocześnie nie implementują problemów wynikających z wykorzystania modelu ESB.
Jakie problemy rozwiązują mikroserwisy?
Mikroserwisy są przede wszystkim sposobem na zwiększenie wydajności. W przypadku aplikacji monolitycznych proces realizacji usług wymaga bowiem uwzględniania mnóstwa zależności. To znacznie wydłuża czas pracy nad aplikacją i ogranicza skalowalność.
Ponadto, zaprojektowanie całego modelu danych jest niemałym wyzwaniem. Aplikacje budowane w ten sposób mogą powstawać tak długo, że w połowie pracy konieczne stanie się wprowadzenie początkowo nieprzewidzianych zmian. W efekcie trzeba powtórzyć prace na całym modelu. Biznesowo jest to nieopłacalne.
Dużą bolączką systemów opartych na relacyjnym modelu danych są też awarie. Ze względu na relacyjność wszystkim elementów wystarczy awaria jednego, aby aplikacja przestała działać. Wykorzystując mikroserwisy, można się natomiast skupić tylko na tym elemencie, który działa wadliwie.
Warto też podkreślić, że każdy mikroserwis, chociaż działa niezależnie, współpracuje z pozostałymi komponentami nawet, gdy wykorzystuje inne języki czy technologie. Jak to się ma do aplikacji monolitycznych? Nad mikroserwisami można pracować w bardzo zróżnicowanym zespole, który wykorzystuje niejedną technologię i język. Taka różnokierunkowość nie jest możliwa w tradycyjnej architekturze.
Korzyści biznesowe z mikroserwisów
- zapewniają większą kontrolę nad długiem technicznym
- zmniejszają ryzyko zatrzymania pracy nad całą aplikacją z powodu awarii jednego elementu
- zwiększają stabilność systemu
- umożliwiają wybór technologii
- przyśpieszają wdrażanie usługi
- zapewniają skalowalność
- obniżają koszty (poprzez skrócenie cyklu produkcyjnego)
Kiedy mikroserwisy się nie sprawdzają?
Mikroserwisy są rozwiązaniem, które ma wiele zalet, ale należy podkreślić, że ich wdrożenie wymaga ogromu pracy. Jest to szczególnie zauważalne w zmianach organizacyjnych, które należy wprowadzić w zespole. Aby mikroserwisy się sprawdziły, trzeba bowiem zmienić nie tylko sposób pracy aplikacji, ale też sposób pracy ludzi. Jednostki biznesowe muszą zacząć autonomiczną realizację projektów i zapomnieć o większości aspektów tradycyjnego modelu pracy. Co więcej, praca w imię zasady “design for failure” jest koniecznością.
Należy też podkreślić, że liczba mikroserwisów, chociaż nie zawsze są to systemy naprawdę mikro, nie powinna być zbyt duża. Aby usługi się ze sobą komunikowały i dobrze działały w rozproszeniu, warto tę sprawę poważnie przemyśleć. Niektórzy wpadają w pułapkę setek mikroserwisów, których sprawna obsługa jest prawie niemożliwa, a poziom SLA pozostawia wiele do życzenia. To droga donikąd.
Kiedy wdrażać mikroserwisy?
Mikroserwisy mają albo wielkich fanów, albo zagorzałych przeciwników. Brak porozumienia między tymi grupami wynika z niejednorodności tego typu architektury. Z jednej strony zapewnia ona wiele korzyści biznesowych, ale może też okazać się wyzwaniem nie do sprostania.
Jak temu zapobiec? Przede wszystkim warto skorzystać z usług wdrożeniowych doświadczonej w tym zakresie firmy. Zespół specjalistów wybierze najlepszą opcję dla Twojego biznesu i możliwe, że nie zawsze będą to mikroserwisy. Można też pomyśleć nad hybrydą, czyli nad zastosowaniem monolitycznej architektury tam, gdzie ma to sens. Tyczy się to np. transakcji biznesowych, które ze względu na swój charakter aktualizują wiele jednostek, a to wymaga spójności programowej. W pozostałych przypadkach można zaś oprzeć pracę na technologii mikroserwisów.
Co to są aplikacje cloud-native?
Termin cloud-native można przetłumaczyć jako natywny dla chmury. Określenie to odnosi się do podejścia do tworzenia oprogramowania, które wykorzystuje technologię przetwarzania w chmurze. Aplikacje budowane są od początku z myślą o chmurze i z wykorzystaniem jej architektury oraz technologii (np.: mikroserwisy, kontenery, serverless). Systemy cloud-native korzystają z dostępnych w chmurze usług zarządzanych i narzędzi do automatyzacji.
Rozwiązania natywne dla chmury złożone są z luźno powiązanych systemów (mikroserwisów) które w przeciwieństwie do aplikacji monolitycznych, można szybko budować, wdrażać, skalować, a także wygodnie nimi zarządzać. Programowanie natywne dotyczy zarówno chmur publicznych, jak i prywatnych.
Jakie są zalety aplikacji cloud-native?
Natywne aplikacje chmurowe posiadają wszystkie zalety rozwiązań chmurowych:
- skalowalność – pozwalają z łatwością dopasować zasoby do zapotrzebowania, zapewniając nieprzerwany i płynny dostęp do usług użytkownikom,
- szybkość tworzenia – skracają czas tworzenia, usprawniania i publikacji dzięki wykorzystaniu mikrousług, strumieni ciągłej integracji / ciągłego dostarczania (CI / CD) oraz gotowych narzędzi typu open-source,
- usprawnienie pracy – likwidują konieczność zajmowania się konfiguracją i utrzymaniem infrastruktury serwerowej i sieciowej dzięki wykorzystaniu usług serverless,
- elastyczność i efektywność – można dużo szybciej je rozbudowywać o nowe funkcje, łatwiej konfigurować oraz przenosić miedzy środowiskami, a w rezultacie szybciej wdrażać na rynek,
- bezpieczeństwo – dzięki kopiom zapasowym w sieci oraz rozproszeniu geograficznym centrów danych są odporne na awarie i minimalizują ryzyko utraty danych.
Co to jest wirtualizacja?
Wirtualizacja to proces logicznego podzielenia fizycznego urządzenia (np. serwera) na mniejsze wirtualne jednostki. Oprogramowanie zwane hiperwizorem pozwala podzielić zasoby fizyczne na jednej maszynie na wiele maszyn wirtualnych (VM). Każda maszyna wirtualna staje się osobnym obszarem, na którym można uruchomić osobne środowisko ze swoim systemem operacyjnym.
Wirtualizacja jest podstawową technologią wykorzystywaną w cloud computingu. Pozwala dzielić i błyskawicznie przydzielać zasoby pomiędzy wieloma systemami w zależności od potrzeb. Dzięki skalowalności chmury możemy wygodnie zarządzać pamięcią i optymalnie wykorzystać serwery.
Jakie korzyści stwarza wirtualizacja?
Celem wirtualizacji jest zyskanie niezależności sprzętowej. Mimo iż nie mamy dostępu do sprzętu fizycznego, możemy emulować jego działanie. Dzięki uniezależnieniu od fizycznych serwerów programiści mogą:
- łatwiej administrować zasobami fizycznymi i zapewnić ich bardziej optymalne wykorzystanie,
- zautomatyzować procesy i uprościć wprowadzanie nowych rozwiązań informatycznych,
- wygodnie równoważyć obciążenia aplikacji, przenosząc je na bardziej wydajne serwery, a dzięki temu eliminować przestoje (np. w razie awarii sprzętu),
- zyskać w pełni skalowalne środowisko i zwiększyć wydajność pracy,
- tworzyć lub kopiować środowisko testowe, eliminując potrzebę stosowania dedykowanego sprzętu testowego lub nadmiarowych serwerów i ograniczając ryzyko utraty danych,
- zwiększyć poziom bezpieczeństwa sprzętu i ułatwić odzyskiwanie danych w razie awarii,
- obniżyć koszty infrastruktury, ograniczając inwestycje w dodatkowy sprzęt,
- zmniejszyć wydatki operacyjne, redukując obciążenie bieżącą obsługą.