# Jak skonfigurować tzw. healthchecki?
Aby usłudze OTM prawidłowo działały tryby automatyczne, musisz zdefiniować dla każdego serwera odpowiedni healtcheck (zwany także monitorem). Możesz to zrobić bezpośrednio, tworząc odpowiednią konfigurację w usłudze Oktawave Watch, bądź w uproszczony sposób - w trakcie definiowania rekordu w usłudze OTM. Po stworzeniu healthchecka musisz go powiązać z konkretnym serwerem. Takie powiązanie jest możliwe po przełączeniu reguł w tryb automatyczny.
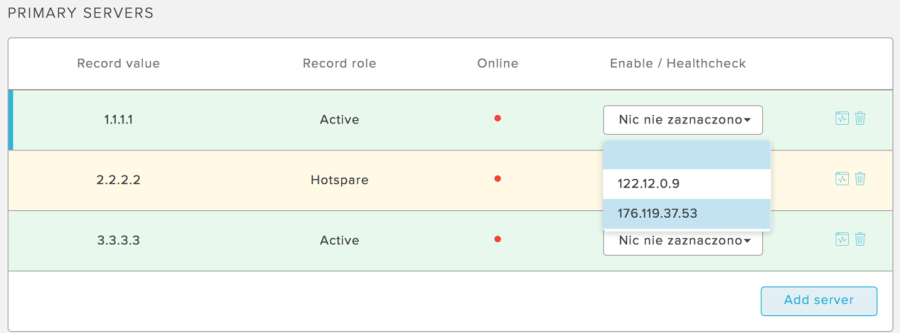
Dopóki nie usuniesz powiązania serwera z healtcheckiem, będzie ono aktywne - niezależnie od ustawienia reguł trybu automatycznego. Po przełączeniu w tryb MANUALNIE nie jest pokazywana informacja o healtchecku i w zamian pojawia się przycisk do ręcznego przełączenia. Kolumna online będzie aktualizowana zgodnie z rzeczywistym stanem healtchecka, ale nie będzie implikowała zmian w rekordzie domeny. Dzięki temu będziesz wiedział, czy możesz bezpiecznie w trybie ręcznym z powrotem przełączyć ruch na wybrane serwery.
W ramach konfiguracji healtchecka w usłudze Oktawave Watch możesz określić protokół testu, częstotliwość sprawdzeń (min. 1 minuta), limit czasu odpowiedni i wiele innych parametrów. Zwróć szczególną uwagę na sekcję powiadomienia.
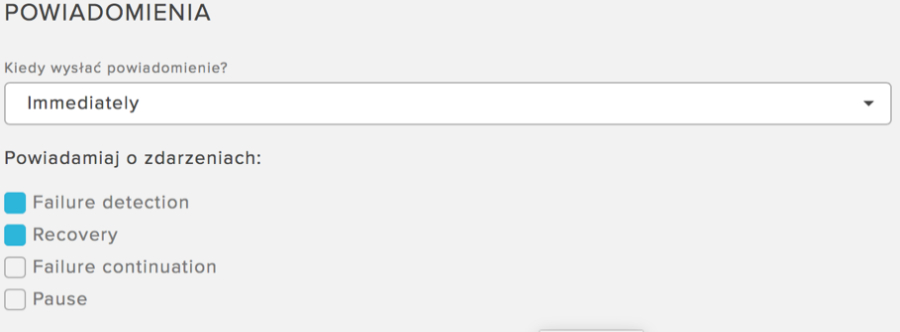
Aby usługa OTM działała prawidłowo, dla każdego healtchecka musi być zaznaczone powiadomienie o awarii (Failure detection) oraz o ustąpieniu awarii (Recover).
W polu Kiedy wysłać powiadomienie możesz zmienić Immediately na np. 10 minut. W taki przypadku usługa OTM wykona zmianę stanu zdefiniowanego i połączonego z healtcheckiem stanu rekordu dopiero po upłynięciu zadanego czasu. Dzięki temu możesz uniknąć tzw. „flappingu" serwerów, tj. niekontrolowanego włączania/wyłączania po każdym sprawdzeniu (taka sytuacja możliwa jest zwykle wtedy, gdy serwery obsługujące Twoją aplikację pracują na granicy swoich możliwości i często zgłaszają błędy).
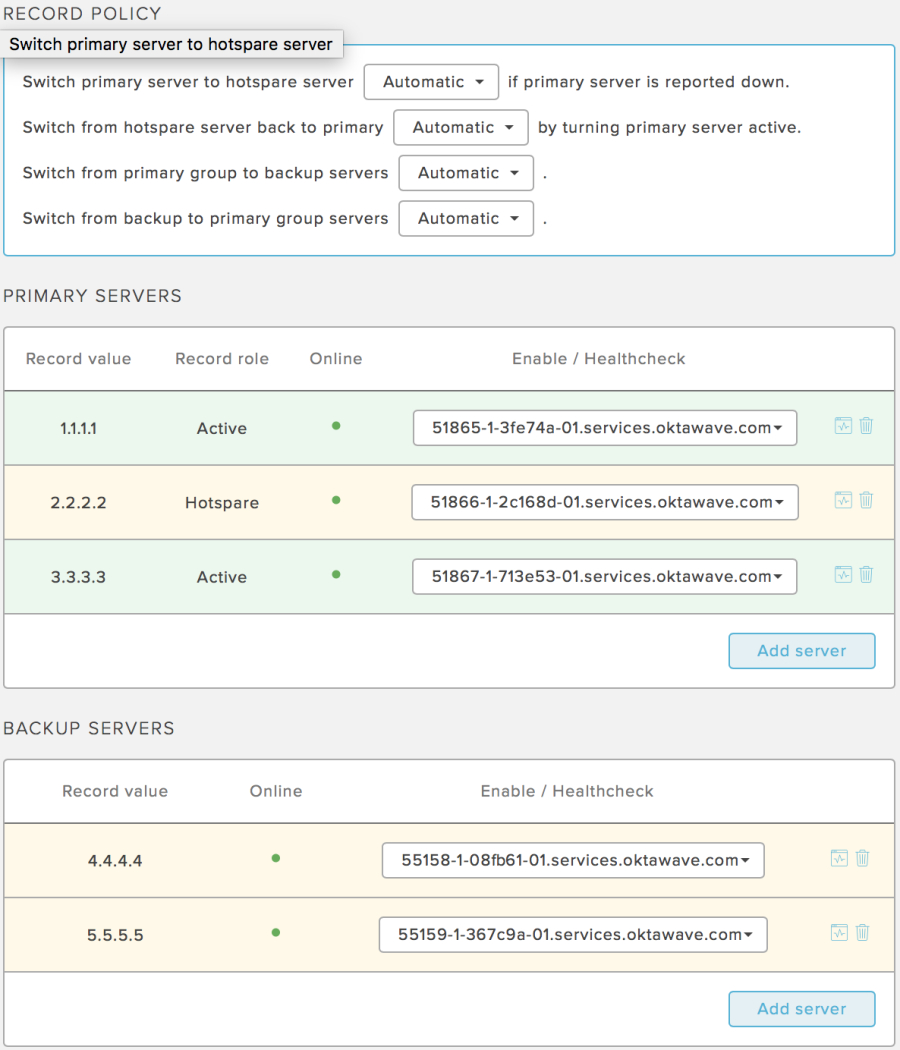
Poniżej znajduje się przykład prawidłowo wykonanej konfiguracji w trybie w pełni automatycznym. W grupie głównej znajdują się dwa serwery aktywne i jeden hotspare. W grupie zapasowej znajdują się dwa serwery. Kolor zielony wskazuje, które serwery obsługują ruch od klientów.
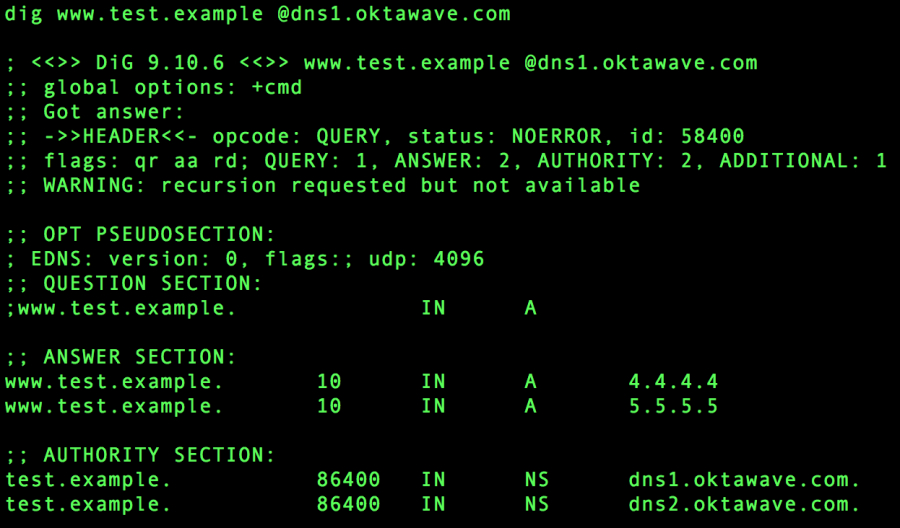
Weryfikacja odpowiedzi usługi.
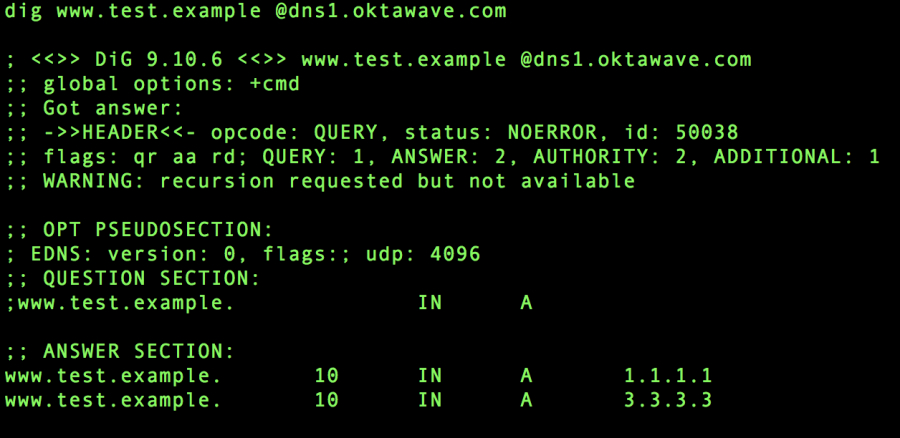
Wystąpienie awarii jednego z serwerów (np. 1.1.1.1).
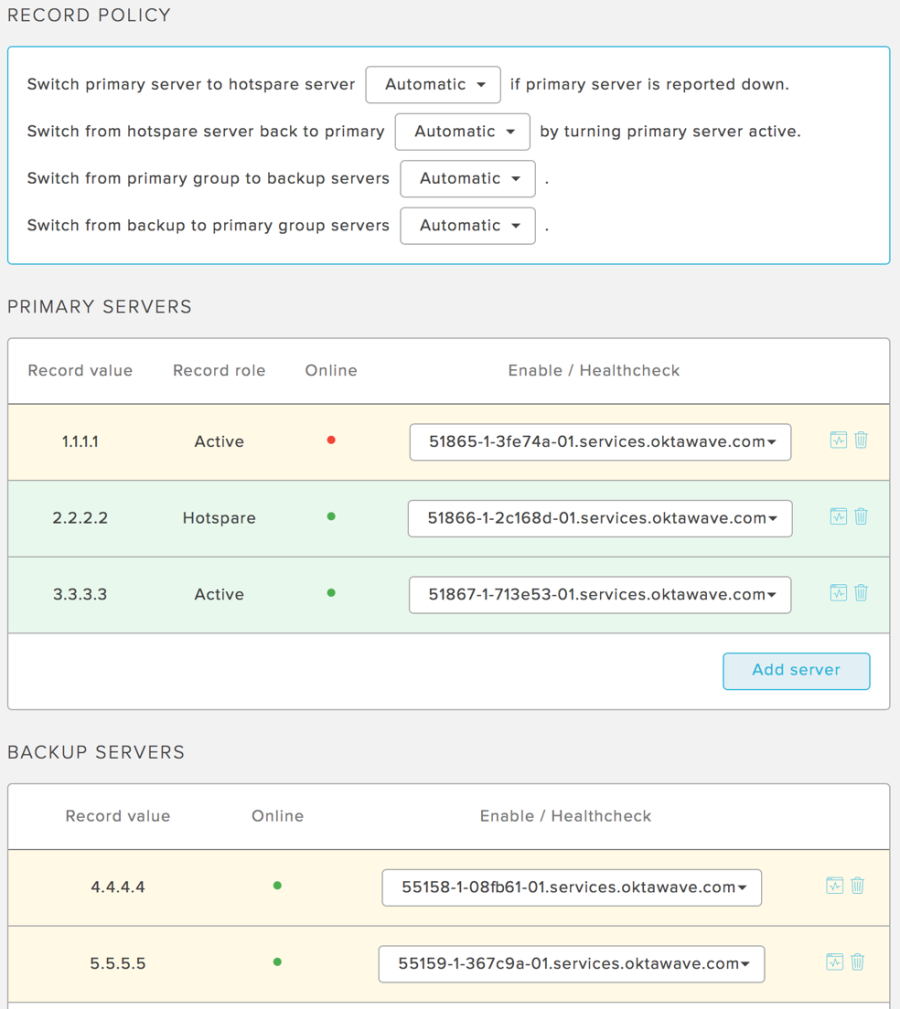
Zwróć uwagę na kolor podświetlenia tła - zielony wskazuje, które serwery obsługują ruch od Twoich klientów.
Weryfikacja odpowiedzi usługi.
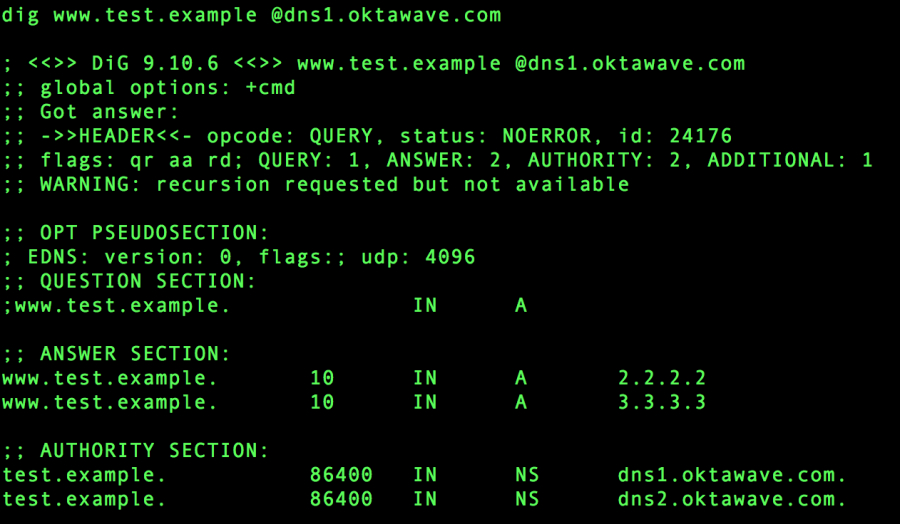
Wystąpienie awarii wszystkich serwerów w grupie głównej i przełączenia na grupę zapasową.
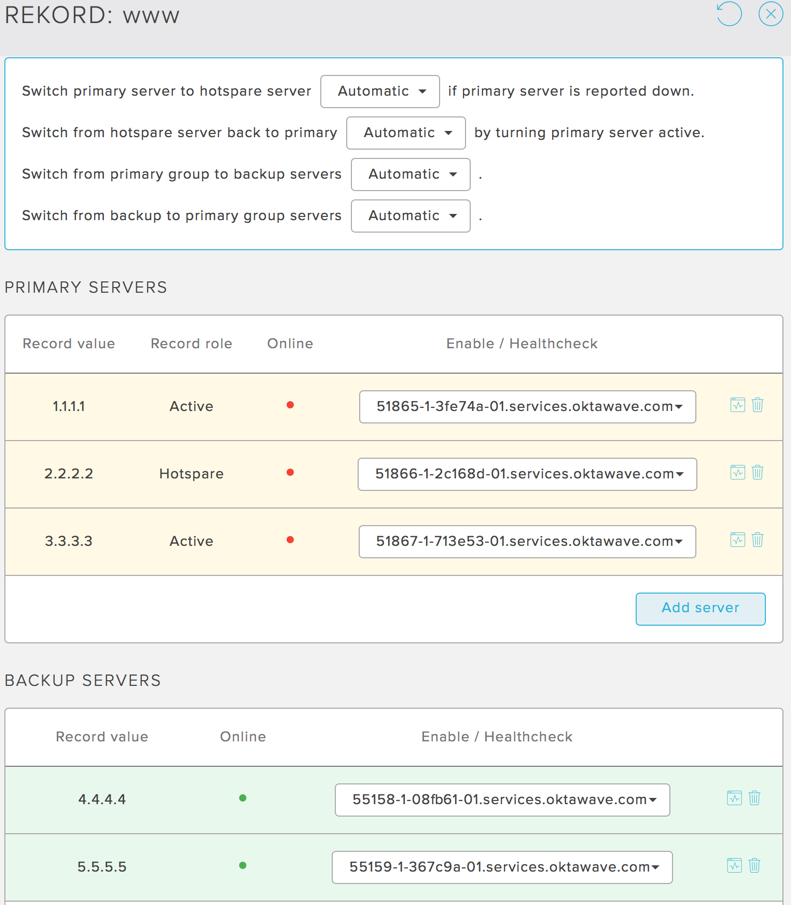
Weryfikacja odpowiedzi usługi.